Cryptanalysis (by alaric)
Ok. We can do better than that. Break our message into 32-bit blocks, then split each block into two 16-bit blocks. Put each one through the S-box. Then take the first byte of the two results and merge them into one 16-bit quantity, and S-box it again, to get the first 16 bits of the output. Then do the same with the last byte of the two results to get the last 16 bits of output.
Now each half of the output depends on three runs through the S-box; the two halves of the input message are run through, then parts of the two outputs are combined and fed in again to produce each half of the output. This means we can't just put different inputs in and get the contents of the S-box read out to us. Also, now with 2^32 = 4 billion possible inputs, it's a lot harder to feed in every input combination in a chosen-plaintext attack to end up with a lookup table of the whole thing.
But with a little thought, we can still find weakness.
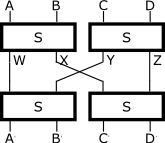
To make the following discussion easier, let's give names to all the values in our algorithm. Say the four inputs bytes are A, B, C, and D. AB and CD are the two 16-bit halves of the block, that are fed into the S-box. The S-box fed with AB outputs a 16 bit quantity, WX. The S-box fed with CD outputs YZ. We then take the first byte of each, getting WY, and feed it into the S-box again, to get A'B', the first two bytes of output. Likewise, we form XZ, S-box it, and get C'D'. The output is then A'B'C'D'.
What if we feed in 65536 chosen plaintexts - keeping the last 16 bits of every block (CD) the same, but trying every possibility for the first 16 bits (AB)?
Since CD is constant, YZ will always be constant while WX changes (because it depends on AB, which changes).
This means that the inputs to the second layer of S-boxes, WY and XZ, are changing only in their first byte. Therefore, as we feed each possible combination of AB in, we will see 256 different output values of A'B' and 256 different output values of C'D'. And we will know that all inputs that caused the same A'B' (regardless of C'D') must have done so because W was the same in all of those cases. If we find all the different values of A'B', then we know that the S-box has the same upper byte output for all those input values. We don't know what those upper bytes are, but we know they're the same. SO we can make a "guess table" of the S-box, and for all inputs that produce the same upper byte on the output, we can write 'U1' (for upper byte value 1) to 'U256') in. Then by looking at sets of inputs that cause the same value of C'D' on the output, we can do the same thing to map out which inputs produce the same lower byte value, and assign them 'L1' to 'L256' entries in the table.
Now we need to figure out what those values are.
We can invert our guess table, to figure out a list of inputs that will produce any chosen value on the first output byte, from U1 to U256, or the second byte, from L1 to L256. Using this information, we can come up with a set of chosen plaintexts that makes WY go through all possible values. WY is composed of the upper bytes of the results of applying the S-box to AB and CD respectively, so by choosing a set of 256 inputs that produce each output value, U1..U256, in turn, then going through all 65536 combinations of them for AB and CD, and seeing what comes out on A'B', we can produce a second guess table that shows, for every combination of two U-values fed into an S-box, what the output is. We can also choose those 65536 combinations so that every possible L-value is produced, too - rather than choosing one input value that outputs U1 and using it 256 times, we can each time choose one that produces a different L-value. So from the same chosen plaintexts we can also examine C'D' to get a table mapping any two L-values to an actual S-box output.
Now we've applied two lots of chosen plaintexts, each 65536 blocks long (so 512KB in total).From this, we have three tables that give us partial information about the S-box; one mapping all possible input values to outputs expressed in terms of pairs of 8-bit U and L symbols, the values of which are not known, and then two tables mapping pairs of U-value inputs or L-value inputs to actual outputs.
This is now actually enough to copy the encryption operation of the cypher; we can choose any input message, use the first table to find WXYZ in terms of U- and L- values, then use the second two tables to get A'B'C'D'. But we really want to find the inverse of the S-box, so we can decrypt messages.
Well, we could do a bit of constraint logic to deduce what the U- and L-values actually are, or we can just invert our tables; for any given encrypted message block, look up in the last two tables to find what pairs of U- and L-values must have been WXYZ, then look up in the first table to find out what ABCD would produce those WXYZ values.
If we do the constraint logic, we can reduce our three 65536-entry tables to a single 65536-entry table that is the actual S-box, though, which will save some space.
![]() Crypto / security | alaric |
Crypto / security | alaric | ![]() Fri 22nd Sep 2006 1:46 pm
Fri 22nd Sep 2006 1:46 pm

By Try the Ghost, Wed 20th Feb 2008 @ 8:34 am
This thread has been dead for quite some time, but if you're still interested, here are my thoughts:
In option 1, you're adding one extra round of S-boxes and diffusion. This buys you an extra avalanche, and therefore a lot more complexity for the attacker. Essentially you've got a three round block cipher with two complete avalanches. No matter how strong your S-boxes, the small number of avalanches will leave it vulnerable to differential cryptanalysis (and possibly other exotic attacks, like impossible linear, and meet in the middle). Your best bet is to have many rounds, so as to increase your total number of avalanches. For me, I'm not satisfied with anything less than 6 complete avalanches. I believe DES had about 5.5, and Blowfish has 7.5. In your case, it takes two passes of S-boxes for the first avalanche, and then one avalanche per round thereafter. However, no matter how many avalanches you have, a 32-bit block cipher is susceptible to a complete "codebook" attack where the interceptor just records plaintext/ciphertext combos for all possible 32-bit inputs -- that table would fit on your iPod several times over.
So option 2 is much stronger. You've now got a 64-bit block cipher. After three rounds you have a complete avalanche, and then every two rounds thereafter (I think). With a 16 round cipher you'd have something like 7.5 full avalanches. Have you considered using several 16-bit S-boxes? In this particular design, 4 separate 16-bit S-boxes would fit quite naturally. Lots more key setup time, but then the attacker is faced with a very, very hard task.
p.s. I loved how you deduced that XORing inputs into an S-box doesn't make the S-box any stronger. In fact, if your S-box is 16 bits and based on only on the user key, then your S-box contains billions of times as much information as your subkeys. Mad entropy, like you said. With key dependent S-boxes, you can scrap subkeys -- they don't add any non-linearity or diffusion, as you so cleanly stated. In my own ciphers, which tend to be based on key dependent S-boxes, I often skip subkeys.
By alaric, Thu 21st Feb 2008 @ 6:58 pm
Yes indeed! I wouldn't recommend using the results of either such options as a 'real cipher', since 32 bit blocks are indeed trivially codebooked, and too few layers of avalanche do ease cryptanalysis greatly. I'm studying them more as basic components, so that their weaknesses can be found and mitigated when using them as parts of a larger whole.
What I've since become more interested in is less linear operations between the S-boxes. Analyses of the implications of a small change in the input, as I've done, rely to a certain extent on the simplicity of the diffusion between layers. While the S-boxes provide a high level of good old key-dependent unguessability, I'm interested in finding functions that efficiently diffuse changes across as much width as possible, with things like key dependence being lower priorities.
See: http://www.snell-pym.org.uk/archives/2005/07/04/avalanche-functions/
I posted my own further examinations of the S-box layering later:
http://www.snell-pym.org.uk/archives/2006/09/24/cryptanalysis-2/#more-311